Hello
On this page you'll find some of my, hopefully helpful, technical post-it's elsewise forgotten.
Cloudflared / Argo shows 127.0.0.1 in Apache httpd logs
2024-dec-22
By default, 127.0.0.1 will be written to Apache httpd logs when clients connect via cloudflared/Argo. To log the real IP of the client, use remoteip:
Cloudflare sends the client IP in the header: "CF-connecting-IP". To use this header information, enable remoteip:
a2enmod remoteip
Add the following configuration to your VirtualHost or server config context:
<VirtualHost *:80>
RemoteIPHeader CF-connecting-IP
...
</VirtualHost>
Restart Apache httpd and verify logs.
"TASK ERROR: start failed: QEMU exited with code 1" Proxmox 8.2.x
2024-jul-19
On Proxmox v8.2.4, my VM with PCI-E passthrough would not boot.
To fix it, I enabled "Relaxed RMRR":
Add "intel_iommu=on" to GRUB_CMDLINE_LINUX_DEFAULT in /etc/default/grub:
GRUB_CMDLINE_LINUX_DEFAULT="quiet intel_iommu=on,relax_rmrr iommu=pt intremap=no_x2apic_optout"
Reload grub conf:
update-grub
Host reboot is required.
Verify after host reboot:
root@pve2:~# dmesg | grep 'Intel-IOMMU'
[ 0.025825] DMAR: Intel-IOMMU: assuming all RMRRs are relaxable. This can lead to instability or data loss
Open WebUI for Ollama installation
2024-may-18
Installing Open WebUI is pretty straightforward:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fssl https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin -y
sudo docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Verify the container is running:
sudo docker ps
The webinterface is now available on the host on port 8080
Proxmox and Ollama runners only hitting CPU, a simple fix
2024-may-18
Spending a few hours debugging and crawling the interwebs, I've found that missing AVX/AVX2 support in the guest VM CPU, will keep Ollama runners on CPU only.
Luckily there is an easy solution to this, which obviously requires hardware support for AVX/AVX2 in the host CPU:
1) Power down the Proxmox VM
2) Navigate to the VMs Hardware-settings
3) Select Processsor and hit Edit
4) In the Type-field, select "Host"
5) Power on the VM
My test-setup hardware:
Proxmox 8.1.4
NVIDIA GeForce GTX 1060 6GB
Intel(R) Core(TM) i7-6800K
NVIDIA-SMI & driver version: 550.54.15
CUDA Version: 12.4
OS: Ubuntu 22.04.4 LTS
Install Ollama and configure it to use GPU:
# Install Ollama:
curl -fsSL https://ollama.com/install.sh | sh
# Reboot VM
reboot
# Check Ollama is running and responding to http at port 11434:
nc -vw1 localhost 11434
# If connecting from remote, do an SSH port forward and connect to http://localhost:1234
ssh -L 1234:127.0.0.1:11434 aners@172.16.16.5
# Install llama3
ollama pull llama3
# Configure which GPU to use with Ollama - get the ID (0, 1, etc.) of the GPU:
nvidia-smi -L
# Add GPU ID to service file:
nano /etc/systemd/system/ollama.service
# Add this line (having multiple 'Environment'-lines is fine), with the GPU ID, in this example GPU id is '0':
Environment="CUDA_VISIBLE_DEVICES=0"
# Reload unit:
systemctl daemon-reload
ollama run llama3
# Watch GPU load:
watch -n 0.5 nvidia-smi
Proxmox "No IOMMU detected, please activate it"
2024-may-18
Enable IOMMU for Intel CPUs in Proxmox via GRUB:
Add "intel_iommu=on" to GRUB_CMDLINE_LINUX_DEFAULT in /etc/default/grub:
GRUB_CMDLINE_LINUX_DEFAULT="quiet intel_iommu=on"
Reload grub conf:
update-grub
Host reboot is required.
Proxmox "USB disconnect"
2024-apr-04
Having experienced a USB-drive suddenly disconnect from my Proxmox (8.1.10) host, disabling autosuspend seemingly resolved the issue.
Add "usbcore.autosuspend=-1" to GRUB_CMDLINE_LINUX_DEFAULT in /etc/default/grub:
GRUB_CMDLINE_LINUX_DEFAULT="quiet usbcore.autosuspend=-1"
Reload grub conf:
update-grub
Host reboot is required.
fatal trap 12: page fault while in kernel mode - vSRX and Proxmox
2024-apr-03
Migrating a vSRX (18.3R1.9) from ESXi-7 to Proxmox-8.1.10 with the migration tool recently released, the vSRX migrated fails to boot with the error message:
fatal trap 12: page fault while in kernel mode
To resolve this, power off the vSRX-VM and:
1) Ensure virtualization is enabled on the host *
2) Set "Machine" to "q35" under VM Hardware
3) Add args to VM configuration via shell:
qm set --args "-machine q35,smbios-entry-point-type=32"
Power on the vSRX-VM
* If you're unable to provide virtualization features, don't bother with the vSRX, it will drop packets.
Coral TPU, ESXi USB forwarding
2024-mar-31
-> The following "fix" failed after a few hours. Don't bother, run Proxmox instead.
Having struggled with adding a Coral TPU (USB) to my HomeAssistant via ESXi, i resolved the issue by running Proxmox - however, later I found this article.
Not wanting to reboot my host, I tried adding a hostd-restart to the mix. The following steps ensured I could now use my Coral TPU (USB) in my HAOS VM in ESXi:
1) Power off VM
2) Edit the VM and add a key and value pair:
- 2.1) Edit VM
- 2.2) VM Options tab
- 2.3) Advanced (expand)
- 2.4) Edit Configuration
- 2.5) Add parameter
- 2.6) Set Key to "usb.quirks.device0" =
- 2.7) Set Value to "0x18d1:0x9302 skip-reset, skip-refresh, skip-setconfig"
Make sure the VM has a 3.1 USB Controller
-- Save VM settings --
4) SSH to the ESXi host and run the following commands:
/etc/init.d/usbarbitrator stop
vmkload_mod -u vmkusb;vmkload_mod vmkusb
kill -SIGHUP $(ps -C | grep vmkdevmgr | awk '{print $1}')
/etc/init.d/usbarbitrator start
/etc/init.d/hostd restart
5) Verify that the Coral TPU device ID is correct, by running
lsusb
(and/or)
esxcli hardware usb passthrough device list
6) The device ID should look like this: (18d1:9302) Google Inc
7) Edit the VM again, add the USB devices needed - in this list, the "Google Inc" device should be populated
8) Power on the VM and verify the device ID (vendor and product) is in fact 18d1:9302
Frigate can now access the TPU :)
The service snmpd failed to start (VMware)
2023-dec-12
Error "The service snmpd failed to start" will be displayed if the service has not been configured.
Configure snmpd via ESXi shell as follows:
Reset settings, if any current exists:
esxcli system snmp set -r
Community:
esxcli system snmp set -c aners
Port (udp):
esxcli system snmp set -p 161
Location:
esxcli system snmp set -L "Room 641A"
Contact (email):
esxcli system snmp set -C mail@yourmail.tld
Enable service?
esxcli system snmp set -e yes
Then go to https://esxihost/ui/#/host/manage/services and start the service.
Consider changing the start policy as well.
storcli basic arguments
2023-dec-07
The following arguments are ones I typically use to check drives on a controller with just storcli available for management.
storcli version 007.1017.0000.0000 May 10, 2019
Binary md5: c9d527d39b83583be84244364f8daa8a
Show all drives on all controllers and enclosures:
./storcli /call/eall/sall show
Find failed, copyback'ing, and unconfigured bad across all controllers and enclosures:
./storcli /call/eall/sall show|grep -i "failure|cpybck|failed|ubad"
Locate disk, start:
./storcli /c0/e0/s4 start locate
Locate disk, stop
./storcli /c0/e0/s4 stop locate
Show rebuild status across all controllers and enclosures for each drive:
./storcli /call/eall/sall show rebuild
Show copyback ("Cpybck") status for drive
./storcli /c0/e0/s9 show copyback
More details
here
Airthings Wave Plus LED-ring color, HomeAssistant
2023-nov-24
The
Airthings integration for HomeAssistant doesn't provide the status of the LED-ring in my Airthings Wave Plus. It does fetch the data I need though, and is required for this template.
Luckily Airthings have shared their
thresholds, making it trivial to read data from Entities and making a new Entity for the LED-ring.
My following template is pretty self-explanatory. Edit name of entities to match your installation.
A custom card could be created for changing the color of the ring-icon, but I haven't bothered.
{# Define points counter #}
{% set airthings_bedroom_points = 0 %}
{# Fetch data from sensors #}
{% set airthings_bedroom = {
"co2": states('sensor.airthings_wave_airthingsbedroom_co2')|int|round,
"radon": states('sensor.airthings_wave_airthingsbedroom_radon_1_day_avg')|int|round,
"voc": states('sensor.airthings_wave_airthingsbedroom_voc')|int|round,
"humidity": states('sensor.airthings_wave_airthingsbedroom_humidity')|int|round
}%}
{# Co2 thresholds#}
{% if airthings_bedroom.co2 > 1000 %}
{# Co2 level RED #}
{% set airthings_bedroom_points = airthings_bedroom_points + 10 %}
{% elif airthings_bedroom.co2 > 800 %}
{# Co2 level YELLOW#}
{% set airthings_bedroom_points = airthings_bedroom_points + 2 %}
{% else %}
{# Co2 level GREEN, don't add to points #}
{% endif %}
{# Radon thresholds#}
{% if airthings_bedroom.radon > 150 %}
{# Radon level RED #}
{% set airthings_bedroom_points = airthings_bedroom_points + 10 %}
{% elif airthings_bedroom.radon > 100 %}
{# Radon level YELLOW#}
{% set airthings_bedroom_points = airthings_bedroom_points + 2 %}
{% else %}
{# Radon level GREEN, don't add to points #}
{% endif %}
{# VOC thresholds#}
{% if airthings_bedroom.voc > 2000 %}
{# VOC level RED #}
{% set airthings_bedroom_points = airthings_bedroom_points + 10 %}
{% elif airthings_bedroom.voc > 250 %}
{# VOC level YELLOW#}
{% set airthings_bedroom_points = airthings_bedroom_points + 2 %}
{% else %}
{# VOC level GREEN, don't add to points #}
{% endif %}
{# Humidity thresholds#}
{% if airthings_bedroom.humidity > 70 or airthings_bedroom.humidity < 25 %}
{# Humidity level RED #}
{% set airthings_bedroom_points = airthings_bedroom_points + 10 %}
{% elif airthings_bedroom.humidity > 60 %}
{# Humidity level YELLOW#}
{% set airthings_bedroom_points = airthings_bedroom_points + 2 %}
{% elif airthings_bedroom.humidity < 30 %}
{# Humidity level YELLOW#}
{% set airthings_bedroom_points = airthings_bedroom_points + 2 %}
{% else %}
{# Humidity level GREEN, don't add to points #}
{% endif %}
{# Ring color human#}
{% if airthings_bedroom_points > 9 %}
{# Ring RED #}
{% set airthings_bedroom_ring = 'Rød' %}
{% elif airthings_bedroom_points > 1 %}
{# Ring YELLOW#}
{% set airthings_bedroom_ring = 'Gul' %}
{% else %}
{# Ring GREEN, don't add to points #}
{% set airthings_bedroom_ring = 'Grøn' %}
{% endif %}
{{ airthings_bedroom_ring }}
Module 'CPUID' power on failed. (VMware)
2023-nov-17
Even though the number of configured vCPUs in the VM wasn't changed nor excessive, a VM wouldn't cross-migrate (got an EVC error) hot.
After powering off the VM and migrating to another cluster, which was on the same EVC level, powering on the VM resulted in the error "Module 'CPUID' power on failed."
Inspecting the CPU Identification Mask settings (Edit Settings -> CPU > CPUID Mask -> Advanced) and resetting to default did not resolve the issue.
I assumed the VMX had some clues, and found multiple lines of cpuid-related flags:
[aners@derp:/vmfs/volumes/vsan:5..2]grep -i cpu *.vmx:
...
sched.cpu.units = "mhz"
cpuid.80000001.edx = "---- ---- ---0 ---- ---- ---- ---- ----"
cpuid.80000001.eax.amd = "---- ---- ---- ---- ---- ---- ---- ----"
cpuid.80000001.ebx.amd = "---- ---- ---- ---- ---- ---- ---- ----"
cpuid.80000001.ecx.amd = "---- ---- ---- ---- ---- ---- ---- ----"
cpuid.80000001.edx.amd = "---- ---- ---0 ---- ---- ---- ---- ----"
sched.cpu.latencySensitivity = "normal"
...
Removing all 'cpuid...'-lines from the VMX resolved the issue, the VM was now able to boot.
vSphere Remove snapshot task 0%, stuck? (VMware)
2023-nov-10
When removing large snapshots, the task status is progressing towards 100%, or so it should be; sometimes it goes to 0% in the web UI and the user is left clueless.
Updating the web UI doesn't bring the current progress back. Luckyli the shell on the host can be used to retrieve the progress:
Chaining a few commands, will get the progress of the "Snapshot.remove"-task:
1) Get a list of all VMs and filter by the name of your VM: vim-cmd vmsvc/getallvms|grep -i garg|awk '{print $1}'
[root@esxnode1337:/vmfs/volumes/vsan:5...2/4...9] vim-cmd vmsvc/getallvms|grep -i garg|awk '{print $1}' 72
The Vmid is returned, in this example 72
2) Verify the Vmid is in fact the VM you're interested in, fetch it's name: vim-cmd vmsvc/get.summary 72|grep name
[root@esxnode1337:/vmfs/volumes/vsan:5...2/4...9] vim-cmd vmsvc/get.summary 72|grep name
name = "Gargoil",
3) Having verified the Vmid, get the running tasks: vim-cmd vmsvc/get.tasklist 72
(ManagedObjectReference) [
'vim.Task:haTask-72-vim.vm.Snapshot.remove-138283664'
]
4) Copy the vim.Task identifier and get task_info, filter "state" and "progress": vim-cmd vimsvc/task_info haTask-72-vim.vm.Snapshot.remove-138283664|grep "state|progress"
state = "running",
progress = 86,
What the web UI failed to display, is that the "Snapshot.remove"-task is running and 86% complete, I guess this is why CLI is usually my favourite goto.
For more verbose output, remove the pipe to grep
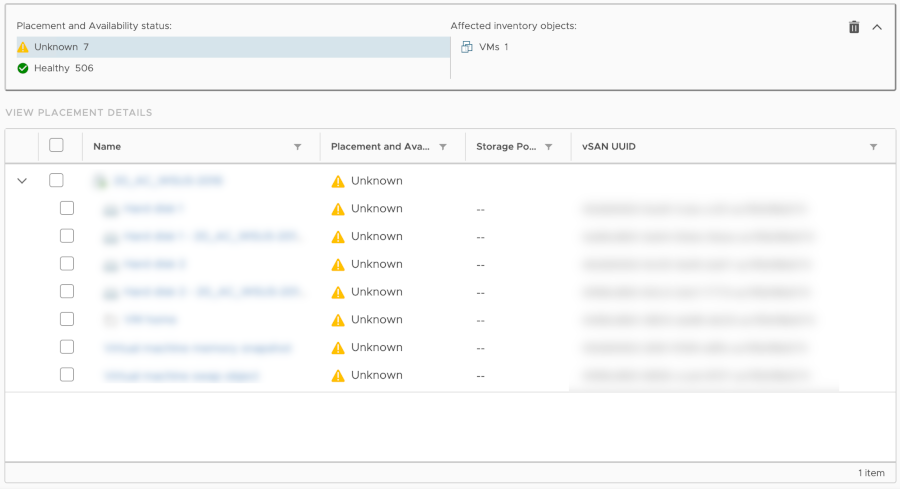
Placement and Availability status Unknown, vSAN (VMware)
2023-nov-09
When "Placement and Availability status" is "Unknown" for storage objects in vSAN, the issue can be as simple as an ISO being mounted from another cluster. If so, unmount the ISO and return to the overview.
Wireguard multiport translation with iptables
2023-nov-07
Consider the following scenario:
Wireguard (daemon) is listening on *:123/udp
Not always a great way out from a hotel network, since NTP is usually rate-limited - sometimes a great way out. Things change.
Instead of deciding on 1 service-port for Wireguard, having Wireguard transparently serve on more ports, seems like a good solution and does not require running multiple interfaces or services.
In the following example, iptables will translate requests coming in at port 8443/udp and redirect them to where Wireguard is actually listening; 123/udp
iptables -t nat -I PREROUTING -i ens160 -d 10.87.132.254/32 -p udp -m multiport --dports 8443 -j REDIRECT --to-ports 123
Now connecting to :8443/udp (and still 123/udp, obviously) will access Wireguard, just that it's translated internally.
I don't recommend using 123/udp. The mentioned rate-limit, often implemented to limit DNS amplification attacks, greatly reduces performance
Creating a fifo-based ffmpeg service
2023-oct-25
I needed an encoder-service waiting to handle ffmpeg-workloads, and decided to use systemctl and a fifo pipe, so jobs could be queued without the need of RabbitMQ/other.
I'm aware of DLQ and fancy scaling, however this does the trick and hasn't failed for years.
1) Create script for initiating the fifo pipe, save it at /opt/createWorkerPipe.sh:
#!/bin/bash
# Pipe location
pipe=/tmp/ffmpeg-pipe
trap "rm -f $pipe" EXIT
# Initiate pipe
[[ -p $pipe ]] || mkfifo $pipe
while true; do
exec 3<> $pipe
read line < $pipe
bash <<< "/opt/ffmpeg-worker.sh $line"
done
2) Create your ffmpeg-worker, with your ffmpeg args, at /opt/ffmpeg-worker.sh:
#!/bin/bash
# Do ffmpeg stuff
/usr/bin/ffmpeg -y input.avi [yourargs] output.mp4
3) Create service file at /etc/systemd/system/ffmpeg-encoder.service:
[Unit]
Description=ffmpeg encoder service
DefaultDependencies=no
After=network.target
[Service]
Type=simple
User=www-data
Group=www-data
ExecStart=/opt/createWorkerPipe.sh:
TimeoutStartSec=0
RemainAfterExit=yes
[Install]
WantedBy=default.target
4) Reload systemctl daemon: systemctl daemon-reload
5) Enable service: systemctl enable ffmpeg-encoder.service
Verify the service state with: systemctl status ffmpeg-encoder.service
Verifying service status programatially can be done by running:
systemctl is-active --quiet ffmpeg-encoder.service
where exitcode 0 is the active state of the service.
I also wrote a simple ffmpeg-log-parser for polling state via PHP, but that's for another post.
Wasabi API, polling active storage
2023-oct-23
Programatically fetching your quota/active utilization, etc. from Wasabi (wasabi.com) is pretty straightforward with their API.
1) Create a user at https://console.wasabisys.com/users with API-access
2) Create access keys for new subuser and assign permissions via policies.
My user has the following policies assigned:
WasabiReadOnlyAccess, WasabiViewAuditLogs, WasabiViewBillingAccess, WasabiViewEventNotifications
Query Wasabi's API like so:
curl -H "Authorization: ACCESS-KEY:SECRET-KEY" https://billing.wasabisys.com/utilization
Note that no type of Authorization is set, no "Basic", "Digest", etc.
Getting this via jQuery is trivial, I've written a simple script for it you can try out:
<html>
<head>
<script src="https://code.jquery.com/jquery-3.7.1.min.js" crossorigin="anonymous"></script>
<script>
$.ajaxSetup({
headers : {
'Authorization' : 'ACCESS-KEY:SECRETKEY'
}
});
function fetchWasabiInfo() {
$.getJSON('https://billing.wasabisys.com/utilization', function(data) {
// Get the latest utilization data from the returned array
latest = $(data).last();
// Calculate current active storage
var PaddedStorageSizeBytes = latest[0]['PaddedStorageSizeBytes'];
var MetadataStorageSizeBytes = latest[0]['MetadataStorageSizeBytes'];
var ActiveStorage = (PaddedStorageSizeBytes + MetadataStorageSizeBytes) / 1024 / 1024 / 1024 / 1024;
// Output result to div, 2 decimals
$('#wasabi-result').text('Active Storage: ' + ActiveStorage.toFixed(2) + 'TB');
})
}
// Run function to fetch data from Wasabi
fetchWasabiInfo();
</script>
</head>
<body>
<div id="wasabi-result">Fetching data...</div>
</body>
</html>
Replace ACCESS-KEY and SECRETKEY on line 7 with your credentials.
Reencode and keep aspect ratio, no upscaling, 1280px (ffmpeg)
2023-sep-19
For scaling a video with ffmpeg with a target of 1280px width or height, I use the following filters:
/usr/bin/ffmpeg -loglevel error -stats -y -i INPUT.MOV -vf "scale=iw*min(1\,if(gt(iw\,ih)\,1280/iw\,(1280*sar)/ih)):(floor((ow/dar)/2))*2,pad=ceil(iw/2)*2:ceil(ih/2)*2" -acodec aac -strict experimental -ac 2 -ab 128k -vcodec libx264 -f mp4 -crf 26 -pix_fmt yuv420p OUTPUT.MP4
If the source width or height is less than 1280px, the original dimensions will be kept.
If the source width or height is larger than 1280px, the output is scaled to 1280px
Since scaling requires division by 2, the dimensions are calculated and ensured to add up
Change (both) '1280' to fit your output needs.
Invalid configuration for device '0'. (VMware)
2023-aug-10
One of my Veeam Backup Copy jobs failed for every VM in the job, reporting IO errors:
10/08/2023 08.29.02 :: Processing vSRX-18.3 Error: File does not exist. File: [vSRX-18.3.1D2023-08-09T020227_4DE4.vib].
Failed to open storage for read access.
Storage: [vSRX-18.3.1D2023-08-09T020227_4DE4.vib]. Failed to restore file from local backup. VFS link: [summary.xml].
Target file: [MemFs://frontend::CDataTransferCommandSet::RestoreText_{13faea43-f648-4fee-8abb-630907bd1df7}].
CHMOD mask: [0]. Agent failed to process method {DataTransfer.RestoreText}. ...
The volume holding the VIBs, an external USB-drive forwarded to the Veeam guest within ESXi, was gone. Seemingly a failed drive.
VCSA failed to remove the USB Host device, with the error:
Invalid configuration for device '0'
Not being able to remove a missing device (the USB-controller), even when the VM is powered off, I had no choice but to manually delete it:
Simply remove the VM from the inventory - obviously not deleting it from VMFS.
Locating the device in the .VMX for the VM and removing the line from the configuration:
usb_xhci.autoConnect.device0 = "path:0/1/1/5 host:esxi7.fire-exclamationmark.lan hostId:71 05 57 47 bf 16 10 d6-2c 0e 3c 7c 3f 11 9a f0 autoclean:1 deviceType:remote-host"
After trashing the failed drive, replacing it with a new one, and re-powering the USB-controller, I simply registered the VM via VCSA and started over with the local backup.
I wish it was possible to forcefully remove a virtual device via VCSA
Veeam error "The request failed due to a fatal device hardware error."
2023-jul-19
Veeam suddenly failed backing up one of my VMs, a VM homed at a datastore with multiple other VMs - these VMs were backed up just fine.
My first thought was that the device backing the datastore, an old piece of spinning rust, was about to fail. The S.M.A.R.T.-info from ESXi was no help. Zero errors and an interesting runtime of "42 hours"
Retrying the backup didn't help. This single VM still failed to be backed up.
I tried booting of a live Ubuntu ISO to run fsck and found and `corrected` some bad sectors on the volume. Surely the physical drive will be replaced, but for now the backup can run without errors.
Details:
fsck arguments: -ccfky
ESXi version: 7.0.0, 16324942
VMFS version: 6
Veeam VBR version: 10.0.1.4854
Encrypted storage container with LUKS
2023-jul-12
Create an encrypted container for storage with LUKS
Change the names and paths to reflect your environment and needs
1) Make sure cryptsetup is installed: sudo apt update && apt install cryptsetup -y
2) Create an empty file for the container: sudo dd if=/dev/zero bs=1M of=/path/to/lukscontainer count=10240 (I prefer using a flat file, instead of a device, for portability)
3) Create the LUKS volume within the flat file: sudo cryptsetup luksOpen /path/to/lukscontainer container_crypt
4) Create a filesystem within the LUKS volume: sudo mkfs.ext4 /dev/mapper/container_crypt
5) Create a mountpoint for the container: sudo mkdir -p /storage/container/
6) Mount the container in your newly created mountpoint: sudo mount /dev/mapper/container_crypt /storage/container/
To easily unmount and mount the container in the future, create 2 simple scripts:
luksUnmountContainer.sh:
#!/bin/sh /usr/bin/umount /dev/mapper/container_crypt /sbin/cryptsetup luksClose /dev/mapper/container_crypt
luksMountContainer.sh:
#!/bin/sh /sbin/cryptsetup luksOpen /path/to/lukscontainer container_crypt /usr/bin/mount /dev/mapper/container_crypt /storage/container/
Make the scrips executable with chmod +x luks*Container.sh and run them with ./
Make sure to upgrade your KDF to argon2id (default for latest version at the time of writing):
https://mjg59.dreamwidth.org/66429.html
vSRX license monitoring, the dirty way
2023-jun-27
In case monitoring of vSRX/SRX-licensing isn't available from the official solutions from Juniper, one still might want to be in the know, before Junos stops pushing packets.
Managing a growing number of vSRX'es deployed around the world, I didn't want to manually check licenses. I had to make a quick'n'dirty solution. So I did.
The "solution" is rather simple; create a read-only user in Junos. Run a command via SSH, store the result and repeat. It has been a while, so you'd need some old repo's or rewrite some stuff.
Tested with versions:
php-cli 5.5.9
sed (GNU sed) 4.2.2
0) Create read-only users on each device (assuming 'readonlyuser' in this example) and replace 'SECRETPASSWORD' with your set password for 'readonlyuser'.
0.1) Connect to the devices with ssh to accept their keys. There might be a way to accomplish this blindly, however that is beyond the scope of this post.
1) Create a table for storing license data:
CREATE TABLE `vsrx-licenses` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`timestamp` int(12) DEFAULT NULL,
`host` varchar(64) DEFAULT NULL,
`expirationdate` varchar(10) DEFAULT NULL,
`daystoexpire` int(3) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
2) Create file parseXML.php in /home/derp/vsrx-fetch-license/ :
<?php
// Configure database connection
function connectToDatabase($database) {
$link = mysql_connect("DBHOST","DBUSER","DBPASS");
$db = mysql_select_db($database, $link);
mysql_set_charset('utf8',$link);
}
// Define function to calc days to expire
function daysToExpire($expireDate) {
$todaysDate = date("Y-m-j");
$origin = new DateTime($todaysDate);
$target = new DateTime($expireDate);
$interval = $origin->diff($target);
return $interval->format('%a');
}
// Execute magics
connectToDatabase('DBNAME');
$timeNow = time();
$xmlFile = '/home/derp/vsrx-fetch-license/'.$argv[1];
$licenses = json_decode(json_encode((array) simplexml_load_file($xmlFile)), 1);
$licenseDetails = array_column($licenses, 'feature-summary');
//
$deviceNoExt = substr($argv[1], 0, -4);
$deviceClean = substr($deviceNoExt, 34);
// Clear existing count to reduce db-size, optional
#mysql_query("DELETE FROM `vsrx-licenses`");
foreach ($licenseDetails[0] as $element) {
if ($element['licensed'] != 0 && isset($element['end-date'])) {
$deviceEndDate = $element['end-date'];
$deviceDaysToExpire = daysToExpire($deviceEndDate);
mysql_query("INSERT INTO `vsrx-licenses`
(id, timestamp, host, expirationdate, daystoexpire)
VALUES (null, '$timeNow', '$deviceNoExt', '$deviceEndDate', '$deviceDaysToExpire')") or die(mysql_error());
echo 'License for device '.$deviceNoExt.' expires: '.$deviceEndDate.'
';
}
}
3) Create file fetch-licenses.sh in /home/derp/vsrx-fetch-license/. Replace vsrx01.domain.tld ... with the hostnames of your devices
#!/bin/bash
# Clear old logs
napTime=3
/bin/rm /home/derp/vsrx-fetch-license/*.xml
/usr/bin/php /home/derp/vsrx-fetch-license/wipeDB.php
vsrxDevices=("vsrx01.domain.tld" "vsrx02.domain.tld" "vsrx03.domain.tld")
echo "Fetching licenses..."
for device in ${vsrxDevices[@]}; do
echo "Fetching license details for device $device"
/home/derp/vsrx-fetch-license/vsrx-expect.sh $device > /home/derp/vsrx-fetch-license/$device.xml
/bin/sed -i -n '2,$p' /home/derp/vsrx-fetch-license/$device.xml
/bin/sed -i -n '2,$p' /home/derp/vsrx-fetch-license/$device.xml
/usr/bin/php /home/derp/vsrx-fetch-license/parseXML.php $device.xml
echo "Napping for $napTime seconds..."
sleep $napTime
done
echo "All done!"
4) Add execution to cron:
0 * * * * /bin/bash /home/derp/vsrx-fetch-license/fetch-licenses.sh > /home/derp/vsrx-fetch-license/fetch.log 2>&1
5) Create file vsrx-expect.sh in /home/derp/vsrx-fetch-license/ and replace values.
#!/usr/bin/expect -f
set timeout 20000
match_max 100000
set vsrxhost [lindex $argv 0];
spawn ssh -o "StrictHostKeyChecking=no" readonlyuser@$vsrxhost "show system license usage |display xml|no-more"
expect "Password:"
send "SECRETPASSWORD\r"
expect "*>"
expect eof
If all goes well, the database is updated every hour. Each run takes around 5 minutes in my case. Check the logfile /home/derp/vsrx-fetch-license/fetch.log for details after the first run.
I've added a panel in Grafana:
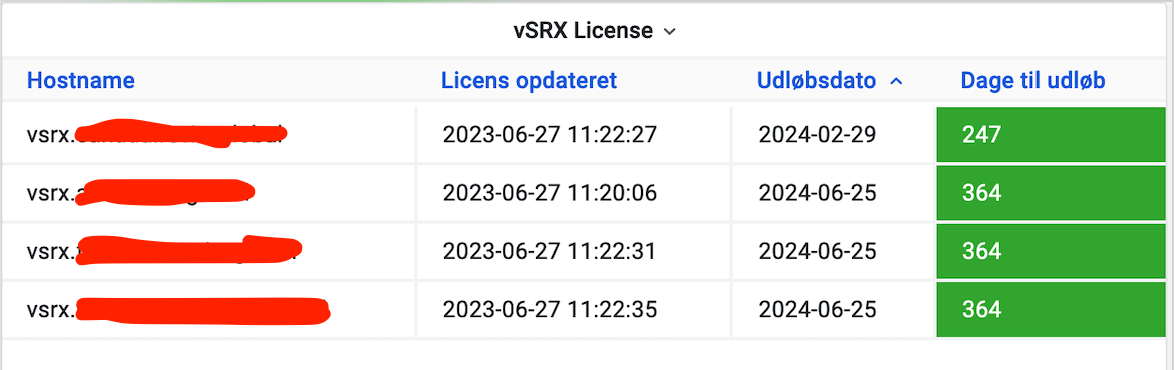
Query is configured as follows:
SELECT host as "Hostname", FROM_UNIXTIME(timestamp-3600) as "Licens opdateret", expirationdate as "Udløbsdato", daystoexpire as "Dage til udløb"
FROM `vsrx-licenses`
ORDER BY daystoexpire asc
Good luck.
Juniper PoE software upgrade
2023-mar-06
To upgrade the PoE controller software in the device, run the following command with your fpc-slot id:
request system firmware upgrade poe fpc-slot 0
To get the status of the upgrade, issue the following command for details:
root> show poe controller
Controller Maximum Power Guard Management Status Lldp
index power consumption band Priority
0** 124W 0.00W 0W DOWNLOAD_INIT Disabled
root> show poe controller
Controller Maximum Power Guard Management Status Lldp
index power consumption band Priority
0** 124W 0.00W 0W SW_DOWNLOAD(43%) Disabled
The download requires no network connectivity, as the sofware is stored on the device.
On my EX2300-C, the download progress went to a halt at 95%, I figured it was simply still installing:
Controller Maximum Power Guard Management Status Lldp
index power consumption band Priority
0** 124W 0.00W 0W SW_DOWNLOAD(95%) Disabled
... a few minutes later, the install process had ended:
Controller Maximum Power Guard Management Status Lldp
index power consumption band Priority
0 124W 0.00W 0W AT_MODE Disabled
As per intructions; "Please Reboot the system after Upgrade is complete"
Junos, match-policies, icmp ping, port 2048
2024-feb-20
Consider the following policy:
security {
policies {
from-zone untrust to-zone junos-host {
policy pub-ping {
match {
source-address any;
destination-address any;
application junos-icmp-ping;
}
then {
permit;
}
}
}
}
}
Security policy details:
Policy: pub-ping, action-type: permit, State: enabled, Index: 20, Scope Policy: 0
Policy Type: Configured
Sequence number: 1
From zone: untrust, To zone: junos-host
Source addresses:
any-ipv4: 0.0.0.0/0
any-ipv6: ::/0
Destination addresses:
any-ipv4(global): 0.0.0.0/0
any-ipv6(global): ::/0
Application: junos-icmp-ping
IP protocol: icmp, ALG: 0, Inactivity timeout: 60
ICMP Information: type=8, code=0
Per policy TCP Options: SYN check: No, SEQ check: No, Window scale: No
When using match-policies in Junos, a match for icmp ping is not found unless the source-port is 2048.
Example matching for source-port 2049 (or any other port):
spiderpig@vsrx-lab> show security match-policies from-zone untrust to-zone junos-host source-ip 1.2.3.4 destination-ip 3.4.5.6 source-port 2049 destination-port 1234 protocol icmp
Policy: deny-all, action-type: deny, State: enabled, Index: 19
0
Policy Type: Configured
Sequence number: 4
From zone: untrust, To zone: junos-host
Source addresses:
any-ipv4: 0.0.0.0/0
any-ipv6: ::/0
Destination addresses:
any-ipv4(global): 0.0.0.0/0
any-ipv6(global): ::/0
Application: any
IP protocol: 0, ALG: 0, Inactivity timeout: 0
Source port range: [0-0]
Destination port range: [0-0]
Per policy TCP Options: SYN check: No, SEQ check: No, Window scale: No
The above result matches the last policy in the sequence, not the one permitting icmp ping
Example matching for source-port 2048:
spiderpig@vsrx-lab> show security match-policies from-zone untrust to-zone junos-host source-ip 1.2.3.4 destination-ip 3.4.5.6 source-port 2048 destination-port 1234 protocol icmp
Policy: pub-ping, action-type: permit, State: enabled, Index: 20
0
Policy Type: Configured
Sequence number: 1
From zone: untrust, To zone: junos-host
Source addresses:
any-ipv4: 0.0.0.0/0
any-ipv6: ::/0
Destination addresses:
any-ipv4(global): 0.0.0.0/0
any-ipv6(global): ::/0
Application: junos-icmp-ping
IP protocol: icmp, ALG: 0, Inactivity timeout: 60
ICMP Information: type=8, code=0
Per policy TCP Options: SYN check: No, SEQ check: No, Window scale: No
The above example matches the policy permitting icmp ping.
Junos version: 18.3R1.9
The test email could not be sent. Check the mail server settings and try again. MSM
2023-feb-20
When sending alerts from MegaRAID Storage Manager (MSM) fails, even though the SMTP-server configuration is correct and the network access is permitted, it might be due to what I believe is a bug in MSM.
I've seen this issue in servers with multiple NICs/servers having changes made to the pNICs after configuring MSM.
In short, the configuration utility does not bind to the correct IP-address/NIC when saving the configuration. This setting is nowhere to be seen in MSM, which is why it took me hours to figure out. To check and potentially fix the issue, do the following:
1) Open MSM and navigate to Tools > Monitor Configure Alerts
2) Make sure the settings for the SMTP-server are correct
3) Click Save Backup, store monitorconfig.xml on the Desktop and click "OK" to close Configure Alerts-dialog
4) Edit monitorconfig.xml with Notepad or another text-editor
5) Find the -tag in the file and set it to the IP-address of the interface that should be used to access the SMTP-server
Example, see last line:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<monitor-config>
<actions>
<popup/>
<email>
<nic>10.106.22.40</nic>
6) Save the file and return to MSM
7) Navigate to Tools > Monitor Configure Alerts
8) Click Load Backup, then Yes, select monitorconfig.xml and click OK
9) Navigate to Tools > Monitor Configure Alerts and test again
Note: The dialog may display "The test email could not be sent. Check the mail server settings and try again." - ignore this and check if the email is delivered within a few minutes.
I don't know the mechanism MSM uses for verifying the email is sent - more often than not, the error displays but the email is delivered anyway.
Versions tested: 16.05.04.01, 17.05.00.02, 17.05.01.03
Avago/LSI/MSM locate failed drive with storcli
2023-feb-16
First use the storcli binary to identify failed drives on each controller (sure, multiple instances of grep could be improved with regex)
./storcli /cALL/eALL/sALL show all|grep Failure|grep -vi predict
Example output:
Status = Failure<br/>/c0/e1/s5 Failure 46 -
Start locating the failed drive:
./storcli /c0/e1/s5 start locate
Example output:
CLI Version = 007.1017.0000.0000 May 10, 2019
Operating system = VMkernel 6.7.0
Controller = 0
Status = Success
Description = Start Drive Locate Succeeded.
Stop locating the failed drive:
./storcli /c0/e1/s5 stop locate
Example output:
CLI Version = 007.1017.0000.0000 May 10, 2019
Operating system = VMkernel 6.7.0
Controller = 0
Status = Success
Description = Stop Drive Locate Succeeded.
To stop locate for all controllers, run the following command:
./storcli /cALL set activityforlocate=off
Deploying vSRX fails: "undefined undefined" in Deployment Type
2023-feb-11
Use ovftool to deploy the image directly to the ESXi-host instead:
ovftool -dm=thick -ds=<DATASTORENAME> -n=<VMNAME> --net:"VM Network"="<VMNETWORKNAME>" "junos-media-vsrx-x86-64-vmdisk-18.2R1.9.scsi.ova" vi://root@esxi-host.tld
Enable IKE debug logging in Junos
2023-feb-11
Enable IKE debug logging in Junos by configuring the following:
set security ike traceoptions file ike-debug
set security ike traceoptions file size 10m
set security ike traceoptions file files 2
set security ike traceoptions flag all
set security ike traceoptions level 15
set security ike traceoptions gateway-filter local-address 10.0.0.123 remote-address 172.16.0.123
The log file is written to /var/log/ - disable the configuration when it's no longer needed, to not wear down the CF/SSD in the device.
Extras:
request security ike debug-enable local 10.0.0.123 remote 172.16.0.123
show security ike traceoptions
show security ike debug-status
Create a RAM-drive in Linux
2023-feb-11
Add the following line to /etc/fstab to create an 8 GB RAM-drive in Linux with tmpfs
tmpfs /mnt/ramdisk tmpfs defaults,size=8192M 0 0
Mount with sudo mount -a and use /mnt/ramdisk/
ESXi stuck snapshot, get task details with vim-cmd
2023-feb-11
If a snapshot seems stuck, use the console to verify a task is actually running:
1) Run vim-cmd vmsvc/getallvms and note the relevant VM-ID
2) Run vim-cmd vmsvc/get.tasklist
and note the Task-id
3) Run vim-cmd vimsvc/task_info to get task status
4) Browse to the VMs location on the datastore and run watch -d 'ls -lut | grep -E "delta|flat|sesparse"' to monitor the process
Unmap VMFS using esxcli
2023-feb-11
First fetch a list of VMFS:
esxcli storage filesystem list
For VMFS' where unmapping is supported, run:
esxcli storage vmfs unmap --volume-label=<label> | --volume-uuid=<uid> [--reclaim-unit=<blocks>]
Junos, save dump to pcap-file
2023-feb-11
To save monitoring to a pcap-file in Junos, use the write-file argument:
monitor traffic interface ge-0/0/1.0 write-file test.pcap
The file will be saved in /cf/var/home//test.pcap
To read back the file in the Junos CLI, use the read-file argument:
monitor traffic read-file test.pcap
ESXTOP xterm, for unsupported terminals
2023-feb-11
Set TERM to xterm, before running esxtop to get a usable output, when the terminal/tty is not supported; run the following command to do so:
TERM=xterm esxtop
Get Virtual Machine uptime, with vim-cmd (VMware)
2023-feb-11
Run:
vim-cmd vmsvc/getallvms to get a list of VM IDs (pipe to grep -i to filter)
With the ID from the second column, use the following command to fetch the uptime (replace 12345 with your VMs ID)
vim-cmd vmsvc/get.summary 12345 |grep "uptimeSeconds"
ffmpeg, crop video
2023-feb-11
Crop 8 seconds of a video, starting from 3 seconds, using the copy method (no reencode)
ffmpeg -i input.mp4 -ss 00:00:03 -t 00:00:08 -c copy output-crop.mp4
Juniper EX3400 boot loop, cannot find kernel
2023-feb-11
EX3400 is boot looping. The kernel cannot be found, reinstall is required.
Power off the EX3400 and:
1) Download the appropriate image for the device (ex: "junos-install-media-usb-arm-32-15.1X53-D59.4-limited.img.gz")
2) Extract the image
3) Write the extracted image to a USB-device using dd with bs=1m or bs=1M depending on version
4) Insert the USB-device and power on the EX3400
5) Hit 5 for [M]ore options and 5 again for [B]oot prompt
6) Run lsdev and confirm device disk1s1a exists
7) Run set currdev="disk1s1a"
8) Run include /boot/loader.rc to reboot the device
9) Wait for the installation to complete -
be patient.
ESXi 6.5, switch to legacy USB-stack
2023-feb-11
Disable vmkusb module in ESXi 6.5 and switch to legacy stack:
esxcli system module set -m=vmkusb -e=FALSE
Reenable vmkusb:
esxcli system module set -m=vmkusb -e=TRUE
Host reboot required
ESXi 6.5, poor SATA performance with native driver
2023-feb-11
Disable native driver and revert to sata-ahci:
esxcli system module set --enabled=false --module=vmw_ahci
Reenable native driver from sata-ahci:
esxcli system module set --enabled=true --module=vmw_ahci
Host reboot required
Simple pyproxy TCP example
2023-feb-11
Script source: download here
./pyproxy.py --tcp -s 172.16.16.81:12345 -d domain.tld:12345 -v
Reboot Netgear CPE/modem/router from command-line
2023-feb-11
Use wget and perl to reboot a Netgear ISP provided CPE/modem/router from comandline.
Replace IP-address and 'REALPASSWORD' with your own settings
id=$(wget --quiet -O- --http-user admin --http-password password http://192.168.100.1/RouterStatus.htm | perl -lne '/id=([0-9]+)/ && print $1'); wget --quiet --http-user admin --http-password REALPASSWORD --post-data 'buttonSelect=2' http://192.168.100.1/goform/RouterStatus?id="$id"
Convert PEM certificate to PFX certificate using OpenSSL
2023-feb-11
openssl pkcs12 -inkey certificate.key -in certificate.pem -export -out certificate.pfx
The requested apache plugin does not appear to be installed
2023-feb-11
Install the plugin for parsing Apache httpd config files:
sudo apt install python3-certbot-apache